

V. Production de code▲
Nous nous intéressons ici à la dernière phase de notre compilateur, la production de code. Dans ce but, nous présentons certains aspects de l'architecture des machines (registres et mémoire, adresses, pile d'exécution, compilation séparée et édition de liens, etc.) et en même temps nous introduisons une machine virtuelle, la machine Mach 1, pour laquelle notre compilateur produit du code et dont nous écrirons un simulateur.
Faute de temps, nous faisons l'impasse sur certains aspects importants (et difficiles) de la génération de code, et notamment sur les algorithmes pour l'optimisation du code et pour l'allocation des registres.
V-A. Les objets et leurs adresses▲
V-A-1. Classes d'objets▲
Dans les langages qui nous intéressent les programmes manipulent trois classes d'objets :
- Les objets statiques existent pendant toute la durée de l'exécution d'un programme ; on peut considérer que l'espace qu'ils occupent est alloué par le compilateur pendant la compilation(52).
Les objets statiques sont les fonctions, les constantes et les variables globales. Ils sont garnis de valeurs initiales : pour une fonction, son code, pour une constante, sa valeur et pour une variable globale, une valeur initiale explicitée par l'auteur du programme (dans les langages qui le permettent) ou bien une valeur initiale implicite, souvent zéro.
Les objets statiques peuvent être en lecture seule ou en lecture-écriture(53). Les fonctions et les constantes sont des objets statiques en lecture seule. Les variables globales sont des objets statiques en lecture-écriture.
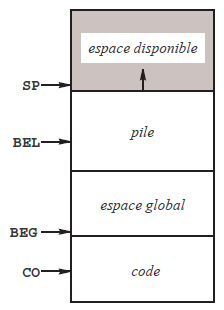
On appelle espace statique l'espace mémoire dans lequel sont logés les objets statiques. Il est généralement constitué de deux zones : la zone du code, où sont les fonctions et les constantes, et l'espace global, où sont les variables globales.
L'adresse d'un objet statique est un nombre entier qui indique la première (parfois l'unique) cellule de la mémoire occupée par l'objet. Elle est presque toujours exprimée comme un décalage(54) par rapport au début de la zone contenant l'objet en question. - Les objets automatiques sont les variables locales des fonctions, ce qui comprend :
Ces variables occupent un espace qui n'existe pas pendant toute la durée de l'exécution du programme, mais uniquement lorsqu'il est utile. Plus précisément, l'activation d'une fonction commence par l'allocation d'un espace, appelé espace local de la fonction, de taille suffisante pour contenir ses arguments et ses variables locales (plus un petit nombre d'informations techniques additionnelles expliquées en détail à la section 5.2.4Compléments sur l'appel des fonctions).
Un espace local nouveau est alloué chaque fois qu'une fonction est appelée, même si cette fonction était déjà active et donc qu'un espace local pour elle existait déjà (c'est le cas d'une fonction qui s'appelle elle-même, directement ou indirectement). Lorsque l'activation d'une fonction se termine son espace local est détruit.
La propriété suivante est importante : chaque fois qu'une fonction se termine, la fonction qui se termine est la plus récemment activée de celles qui ont été commencées et ne sont pas encore terminées. Il en découle que les espaces locaux des fonctions peuvent être alloués dans une mémoire gérée comme une pile (voyez la ) : lorsqu'une fonction est activée, son espace local est créé au-dessus des espaces locaux des fonctions actives (i.e. commencées et non terminées) à ce moment-là. Lorsqu'une fonction se termine, son espace local est celui qui se trouve au sommet de la pile et il suffit de le dépiler pour avoir au sommet l'espace local de la fonction qui va reprendre le contrôle.- les variables déclarées à l'intérieur des fonctions ;
- les arguments formels de ces dernières.
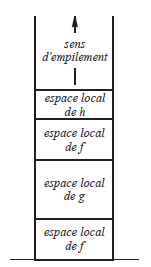
Fig. 14 - Empilement d'espaces locaux (f a appelé g qui a appelé f qui a appelé h) - Les objets dynamiques sont alloués lorsque le programme le demande explicitement (par exemple à travers la fonction malloc de C ou l'opérateur new de Java et C++). Si leur destruction n'est pas explicitement demandée (fonction free de C, opérateur delete de C++) ces objets existent jusqu'à la terminaison du programme(55).
Les objets dynamiques ne peuvent pas être logés dans les zones où sont les objets statiques, puisque leur existence n'est pas certaine, elle dépend des conditions d'exécution. Ils ne peuvent pas davantage être hébergés dans la pile des espaces locaux, puisque cette pile grandit et diminue en accord avec les appels et retours des fonctions, alors que les moments de la création et de la destruction des objets dynamiques ne sont pas connus a priori. On place donc les objets dynamiques dans un troisième espace, distinct des deux précédents, appelé le tas (heap, en anglais).
La gestion du tas, c'est-à-dire son allocation sous forme de morceaux de tailles variables, à la demande du programme, la récupération des morceaux rendus par ce dernier, la lutte contre l'émiettement de l'espace disponible, etc. font l'objet d'algorithmes savants implémentés dans des fonctions comme malloc et free ou des opérateurs comme new et delete.
En définitive, la mémoire utilisée par un programme en cours d'exécution est divisée en quatre espaces (voyez la figure 15) :
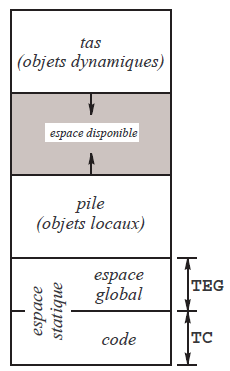
- le code (espace statique en lecture seule), contenant le programme et les constantes ;
- l'espace global (espace statique en lecture-écriture), contenant les variables globales ;
- la pile (stack), contenant variables locales ;
- le tas (heap), contenant les variables allouées dynamiquement.
Les tailles du code et de l'espace global sont connues dès la fin de la compilation et ne changent pas pendant l'exécution du programme. La pile et le tas, en revanche, évoluent au cours de l'exécution : le tas ne fait que grossir(56), la pile grossit lors des appels de fonctions et diminue lors des terminaisons des fonctions appelées.
La rencontre de la pile et du tas (voyez la figure 15) est un accident mortel pour l'exécution du programme.
Cela se produit lorsqu'un programme alloue trop d'objets dynamiques et/ou de taille trop importante, ou bien lorsqu'un programme fait trop d'appels de fonctions et/ou ces dernières ont des espaces locaux de taille trop importante.
V-A-2. D'où viennent les adresses des objets ?▲
Puisque l'adresse d'un objet est un décalage par rapport à la base d'un certain espace qui dépend de la classe de l'objet, du point de vue du compilateur « obtenir l'adresse d'un objet » c'est simplement mémoriser l'état courant d'un certain compteur dont la valeur exprime le niveau de remplissage de l'espace correspondant.
Cela suppose que d'autres opérations du compilateur font par ailleurs grandir ce compteur, de sorte que si un peu plus tard on cherche à obtenir l'adresse d'un autre objet on obtiendra une valeur différente.
Plus précisément, pendant qu'il produit la traduction d'un programme, le compilateur utilise les trois variables suivantes :
TC (Taille du Code) Pendant la compilation, cette variable a constamment pour valeur le nombre d'unités (des octets, des mots, cela dépend de la machine) du programme en langage machine couramment produites.
Au début de la compilation, TC vaut 0. Ensuite, si memoire représente l'espace (ou le fichier) dans lequel le code machine est mémorisé, la production d'un élément de code, comme un opcode ou un opérande, se traduit par les deux affectations :
memoire[TC] ← element
TC ← TC + 1Par conséquent, pour mémoriser l'adresse d'une fonction fon il suffit de faire, au moment où commence la compilation de la fonction :
adresse(fon) ← TCTEG (Taille de l'Espace Global) Cette variable a constamment pour valeur la somme des tailles des variables globales dont le compilateur a rencontré la déclaration.
Au début de la compilation TEG vaut 0. Par la suite, le rôle de TEG dans la déclaration d'une variable globale varg se résume à ceci :
adresse(varg) ← TEG
TEG ← TEG + taille(varg)où taille(varg) représente la taille de la variable en question, qui dépend de son type.
TEL (Taille de l'Espace Local) À l'intérieur d'une fonction, cette variable a pour valeur la somme des tailles des variables locales de la fonction en cours de compilation. Si le compilateur n'est pas dans une fonction TEL n'est pas défini.
À l'entrée de chaque fonction TEL est remis à zéro. Par la suite, le rôle de TEL dans la déclaration d'une variable locale varl se résume à ceci :
adresse(varl) ← TEL
TEL ← TEL + taille(varl)Les arguments formels de la fonction, bien qu'étant des objets locaux, n'interviennent pas dans le calcul de TEL (la question des adresses des arguments formels sera traitée à la section 5.2.4Compléments sur l'appel des fonctions).
À la fin de la compilation les valeurs des variables TC et TEG sont précieuses :
- TC est la taille du code donc, dans une organisation comme celle de la figure 15, elle est aussi le décalage (relatif à l'origine générale de la mémoire du programme) correspondant à la base de l'espace global,
- TEG est la taille de l'espace global ; par conséquent, dans une organisation comme celle de la figure 15, TC + TEG est le décalage (relatif à l'origine générale de la mémoire du programme) correspondant au niveau initial de la pile.
V-A-3. Compilation séparée et édition de liens▲
Tout identificateur apparaissant dans une partie exécutable d'un programme doit avoir été préalablement déclaré. La déclaration d'un identificateur i, que ce soit le nom d'une variable locale, d'une variable globale ou d'une fonction, produit son introduction dans le dictionnaire adéquat, associé à une adresse, notons-la adri. Par la suite, le compilateur remplace chaque occurrence de i dans une expression par le nombre adri.
On peut donc penser que dans le code qui sort d'un compilateur les identificateurs qui se trouvaient dans le texte source ont disparu(57) et, de fait, tel peut être le cas dans les langages qui obligent à mettre tout le programme dans un seul fichier.
Mais les choses sont plus compliquées dans les langages, comme C ou Java, où le texte d'un programme peut se trouver éclaté dans plusieurs fichiers sources destinés à être compilés indépendamment les uns des autres (on appelle cela la compilation séparée). En effet, dans ces langages il doit être possible qu'une variable ou une fonction déclarée dans un fichier soit mentionnée dans un autre. Cela implique qu'à la fin de la compilation il y a dans le fichier produit quelques traces des noms des variables et fonctions mentionnées dans le fichier source.
Notez que cette question ne concerne que les objets globaux. Les objets locaux, qui ne sont déjà pas visibles en dehors de la fonction dans laquelle ils sont déclarés, ne risquent pas d'être visibles dans un autre fichier.
Notez également que le principal intéressé par cette affaire n'est pas le compilateur, mais un outil qui lui est associé, l'éditeur de liens (ou linker) dont le rôle est de concaténer plusieurs fichiers objets, résultats de compilations séparées, pour en faire un unique programme exécutable, en vérifiant que les objets référencés mais non définis dans certains fichiers sont bien définis dans d'autres fichiers, et en complétant de telles références insatisfaites par les adresses des objets correspondants.
Faute de temps, le langage dont nous écrirons le compilateur ne supportera pas la compilation séparée.
Nous n'aurons donc pas besoin d'éditeur de liens dans notre système.
Pour les curieux, voici néanmoins quelques explications sur l'éditeur de liens et la structure des fichiers objets dans les langages qui autorisent la compilation séparée.
Appelons module un fichier produit par le compilateur. Le rôle de l'éditeur de liens est de concaténer (mettre bout à bout) plusieurs modules. En général, il concatène d'un côté les zones de code (objets statiques en lecture seule) de chaque module, et d'un autre côté les espaces globaux (objets statiques en lecture écriture) de chaque module, afin d'obtenir une unique zone de code totale et un unique espace global total.
Un problème apparaît immédiatement : si on ne fait rien, les adresses des objets statiques, qui sont exprimées comme des déplacements relatifs à une base propre à chaque module, vont devenir fausses, sauf pour le module qui se retrouve en tête. C'est facile à voir : chaque module apporte une fonction d'adresse 0 et probablement une variable globale d'adresse 0. Dans l'exécutable final, une seule fonction et une seule variable globale peuvent avoir l'adresse 0.
Il faut donc que l'éditeur de liens passe en revue tout le contenu des modules qu'il concatène et en corrige toutes les références à des objets statiques, pour tenir compte du fait que le début de chaque module ne correspond plus à l'adresse 0 mais à une adresse égale à la somme des tailles des modules qui ont été mis devant lui.
RÉFÉRENCES ABSOLUES ET RÉFÉRENCES RELATIVES. En pratique le travail mentionné ci-dessus se trouve allégé par le fait que les langages machine supportent deux manières de faire référence aux objets statiques.
On dit qu'une instruction fait une référence absolue à un objet statique (variable ou fonction) si l'adresse de ce dernier est indiquée par un décalage relatif à la base de l'espace concerné (l'espace global ou l'espace du code). Nous venons de voir que ces références doivent être corrigées lorsque le module qui les contient est décalé et ne commence pas lui-même, dans le fichier qui sort de l'éditeur de liens, à l'adresse 0.
On dit qu'une instruction fait une référence relative à un objet statique lorsque ce dernier est repéré par un décalage relatif à l'adresse à laquelle se trouve la référence elle-même.
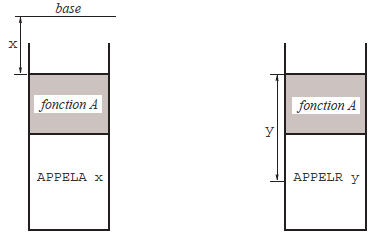
Par exemple, la figure 16 montre le cas d'un langage machine dans lequel il y a deux instructions pour appeler une fonction : APPELA, qui prend comme opérande une référence absolue, et APPELR qui prend une référence relative.
L'intérêt des références relatives saute aux yeux : elles sont insensibles aux décalages du module dans lequel elles se trouvent. Lorsque l'éditeur de liens concatène des modules pour former un exécutable, les références relatives contenues dans ces modules n'ont pas à être mises à jour.
Bien entendu, cela ne concerne que l'accès aux objets qui se trouvent dans le même module que la référence ; il n'y a aucun intérêt à représenter par une référence relative un accès à un objet d'un autre module. Ainsi, une règle suivie par les compilateurs, lorsque le langage machine le permet, est : produire des références intra-modules relatives et des références intermodules absolues.
STRUCTURE DES MODULES. Il nous reste à comprendre comment l'éditeur de liens arrive à attribuer une référence à un objet non défini dans un module (cela s'appelle une référence insatisfaite) l'adresse de l'objet, qui se trouve dans un autre module.
Pour cela il faut savoir que chaque fichier produit par le compilateur se compose de trois parties : une section de code et deux tables faites de couples (identificateur, adresse dans la section de code) :
- la section de code contient la traduction en langage machine d'un fichier source ; ce code comporte un certain nombre de valeurs incorrectes, à savoir les références à des objets externes (i.e. non définis dans ce module) dont l'adresse n'est pas connue au moment de la compilation ;
- la table des références insatisfaites de la section de code ; dans cette table, chaque identificateur référencé mais non défini est associé à l'adresse de l'élément de code, au contenu incorrect, qu'il faudra corriger lorsque l'adresse de l'objet sera connue ;
- la table des objets publics(58) définis dans le module ; dans cette table, chaque identificateur est le nom d'un objet que le module en question met à la disposition des autres modules, et il est associé à l'adresse de l'objet concerné dans la section de code.
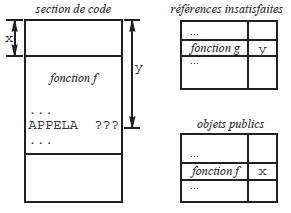
Par exemple, la figure 17 représente un module contenant la définition d'une fonction publique f et l'appel d'une fonction non définie dans ce module g.
En résumé, le travail de l'éditeur de liens se compose schématiquement des tâches suivantes :
- concaténation des sections de code des modules donnés à lier ensemble ;
- décalage des références absolues contenues dans ces modules (dont celles mémorisées dans les tables) ;
- réunion des tables d'objets publics et utilisation de la table obtenue pour corriger les références insatisfaites présentes dans les sections de code ;
- émission du fichier exécutable final, formé du code corrigé.
V-B. La machine Mach 1▲
Nous continuons notre exposé sur la génération de code par la présentation de la machine Mach 1(59), la machine cible du compilateur que nous réaliserons à titre de projet.
V-B-1. Machines à registres et machines à pile▲
Les langages évolués permettent l'écriture d'expressions en utilisant la notation algébrique à laquelle nous sommes habitués, comme X = Y + Z, cette formule signifiant « ajoutez le contenu de Y à celui de Z et rangez le résultat dans X » (X, Y et Z correspondent à des emplacements dans la mémoire de l'ordinateur).
Une telle expression est trop compliquée pour le processeur, il faut la décomposer en des instructions plus simples. La nature de ces instructions plus simples dépend du type de machine dont on dispose. Relativement à la manière dont les opérations sont exprimées, il y a deux grandes familles de machines :
- Les machines à registres possèdent un certain nombre de registres, notés ici R1, R2, etc., qui sont les seuls composants susceptibles d'intervenir dans une opération (autre qu'un transfert de mémoire à registre ou réciproquement) à titre d'opérandes ou de résultats. Inversement, n'importe quel registre peut intervenir dans une opération arithmétique ou autre ; par conséquent, les instructions qui expriment ces opérations doivent spécifier leurs opérandes. Si on vise une telle machine, l'affectation X = Y + Z devra être traduite en quelque chose comme (notant X, Y et Z les adresses des variables X, Y et Z) :
MOVE Y,R1 // déplace la valeur de Y dans R1
MOVE Z,R2 // déplace la valeur de Z dans R2
ADD R1,R2 // ajoute R1 à R2
MOVE R2,X // déplace la valeur de R2 dans X- Les machines à pile, au contraire, disposent d'une pile (qui peut être la pile des variables locales) au sommet de laquelle se font toutes les opérations. Plus précisément :
Pour une telle machine, le code X = Y + Z se traduira donc ainsi (notant encore X, Y et Z les adresses des variables X, Y et Z) :- les opérandes d'un opérateur binaire sont toujours les deux valeurs au sommet de la pile ; l'exécution d'une opération binaire⊗ consiste toujours à dépiler deux valeurs x et y et à empiler le résultat x ⊗ y de l'opération ;
- l'opérande d'un opérateur unaire est la valeur au sommet de la pile ; l'exécution d'une opération unaire ▷consiste toujours à dépiler une valeur x et à empiler le résultat ▷x de l'opération.
PUSH Y // met la valeur de Y au sommet de la pile
PUSH Z // met la valeur de Z au sommet de la pile
ADD // remplace les deux valeurs au sommet de la pile par leur somme
POP X // enlève la valeur au sommet de la pile et la range dans XIl est a priori plus facile de produire du code de bonne qualité pour une machine à pile plutôt que pour une machine à registres, mais ce défaut est largement corrigé dans les compilateurs commerciaux par l'utilisation de savants algorithmes qui optimisent l'utilisation des registres.
Car il faut savoir que les machines « physiques » existantes sont presque toujours des machines à registres, pour une raison d'efficacité facile à comprendre : les opérations qui ne concernent que des registres restent internes au microprocesseur et ne sollicitent ni le bus ni la mémoire de la machine(60). Et, avec un compilateur optimiseur, les expressions complexes sont traduites par des suites d'instructions dont la plupart ne mentionnent que des registres.
Les algorithmes d'optimisation et d'allocation des registres sortant du cadre de ce cours, la machine pour laquelle nous générerons du code sera une machine à pile.
V-B-2. Structure générale de la machine Mach 1▲
La mémoire de la machine Mach 1 est faite de cellules numérotées, organisées comme le montre la figure 18 (c'est la structure de la figure 15, le tas en moins). Les registres suivants ont un rôle essentiel dans le fonctionnement de la machine :
- CO (Compteur Ordinal) indique constamment la cellule contenant l'instruction que la machine est en train d'exécuter ;
- BEG (Base de l'Espace Global) indique la première cellule de l'espace réservé aux variables globales (autrement dit, BEG pointe la variable globale d'adresse 0) ;
- BEL (Base de l'Espace Local) indique la cellule autour de laquelle est organisé l'espace local de la fonction en cours d'exécution ; la valeur de BEL change lorsque l'activation d'une fonction commence ou finit (à ce propos voir la section 5.2.4Compléments sur l'appel des fonctions) ;
- SP (Sommet de la Pile) indique constamment le sommet de la pile, ou plus exactement la première cellule libre au-dessus de la pile, c'est-à-dire le nombre total de cellules occupées dans la mémoire.
V-B-3. Jeu d'instructions▲
La machine Mach 1 est une machine à pile.
Chaque instruction est faite soit d'un seul opcode, elle occupe alors une cellule, soit d'un opcode et un opérande, elle occupe alors deux cellules consécutives. Les constantes entières et les « adresses » ont la même taille, qui est celle d'une cellule. La table 1, à la fin de ce document, donne la liste des instructions.
V-B-4. Compléments sur l'appel des fonctions▲
La création et la destruction de l'espace local des fonctions a lieu à quatre moments bien déterminés : l'activation de la fonction, d'abord du point de vue de la fonction appelante (1), puis de celui de la fonction appelée (2), ensuite le retour, d'abord du point de vue de la fonction appelée (3) puis de celui de la fonction appelante (4). Voici ce qui se passe (voyez la figure 19) :
- La fonction appelante réserve un mot vide sur la pile, où sera déposé le résultat de la fonction, puis elle empile les valeurs des arguments effectifs. Ensuite, elle exécute une instruction APPEL (qui empile l'adresse de retour) ;
- La fonction appelée empile le « BEL courant » (qui est en train de devenir « BEL précédent »), prend la valeur de SP pour BEL courant, puis alloue l'espace local. Pendant la durée de l'activation de la fonction :
L'ensemble de toutes ces valeurs forme l' « espace local » de la fonction en cours. Au-delà de cet espace, la pile est utilisée pour le calcul des expressions courantes.- les variables locales sont atteintes à travers des déplacements (positifs ou nuls) relatifs à BEL : 0 ↔ première variable locale, 1 ↔ deuxième variable locale, etc. ;
- les arguments formels sont également atteints à travers des déplacements (négatifs, cette fois) relatifs à BEL : -3 ↔ n-ème argument, -4 ↔ (n - 1)-ème argument, etc. ;
- la cellule où la fonction doit déposer son résultat est atteinte elle aussi à travers un déplacement relatif à BEL. Ce déplacement est -(n + 3), n étant le nombre d'arguments formels, et suppose donc l'accord entre la fonction appelante et la fonction appelée au sujet du nombre d'arguments de la fonction appelée.
- Terminaison du travail : la fonction appelée remet BEL et SP comme ils étaient lorsqu'elle a été activée, puis effectue une instruction RETOUR.
- Reprise du calcul interrompu par l'appel. La fonction appelante libère l'espace occupé par les valeurs des arguments effectifs. Elle se retrouve alors avec une pile au sommet de laquelle est le résultat de la fonction qui vient d'être appelée. Globalement, la situation est la même qu'après une opération arithmétique : les opérandes ont été dépilés et remplacés par le résultat.
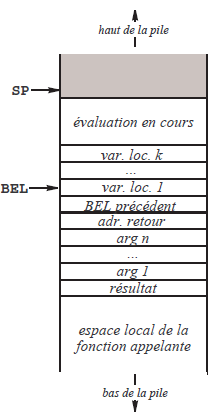
QUI CRÉE L'ESPACE LOCAL D'UNE FONCTION ? Les arguments d'une fonction et les variables déclarées à l'intérieur de cette dernière sont des objets locaux et ont donc des adresses qui sont des déplacements relatifs à BEL (positifs dans le cas des variables locales, négatifs dans le cas des arguments, voir la figure 19). L'explication précédente montre qu'il y a une différence importante entre ces deux sortes d'objets locaux :
- les arguments sont installés dans la pile par la fonction appelante, car ce sont les valeurs d'expressions qui doivent être évaluées dans le contexte de la fonction appelante. Il est donc naturel de donner à cette dernière la responsabilité de les enlever de la pile, au retour de la fonction appelée ;
- les variables locales sont allouées par la fonction appelée, qui est la seule à en connaître le nombre ; c'est donc cette fonction qui doit les enlever de la pile, lorsqu'elles se terminent (l'instruction SORTIE fait ce travail).
LES CONVENTIONS D'APPEL. Il y a donc un ensemble de conventions, dites conventions d'appel, qui précisent à quel endroit la fonction appelante doit déposer les valeurs des arguments et où elle trouvera le résultat ou, ce qui revient au même, à quel endroit la fonction appelée trouvera ses arguments et où elle doit déposer son résultat.
En général les conventions d'appel ne sont pas laissées à l'appréciation des auteurs de compilateurs. Édictées par les concepteurs du système d'exploitation, elles sont suivies par tous les compilateurs « homologués », ce qui a une conséquence très importante : puisque tous les compilateurs produisent des codes dans lesquels les paramètres et le résultat des fonctions sont passés de la même manière, une fonction écrite dans un langage L1, et compilée donc par le compilateur de L1, pourra appeler une fonction écrite dans un autre langage L2 et compilée par un autre compilateur, celui de L2.
Nous avons choisi ici des conventions d'appel simples et pratiques (beaucoup de systèmes font ainsi) puisque :
- les arguments sont empilés dans l'ordre dans lequel ils se présentent dans l'expression d'appel ;
- le résultat est déposé là où il faut pour que, après nettoyage des arguments, il soit au sommet de la pile.
Mais il y a un petit inconvénient(61). Dans notre système, les argument arg1, arg2… argn sont atteints, à l'intérieur de la fonction, par les adresses locales respectives -(n+3)+1, -(n+3)+2… -(n+3)+n = -3, et le résultat de la fonction lui-même possède l'adresse locale -(n+3). Cela oblige la fonction appelée à connaître le nombre n d'arguments effectifs, et interdit l'écriture de fonctions admettant un nombre variable d'arguments (de telles fonctions sont possibles en C, songez à printf et scanf).
V-C. Exemples de production de code▲
Quand on n'est pas connaisseur de la question on peut croire que la génération de code machine est la partie la plus importante d'un compilateur, et donc que c'est elle qui détermine la structure générale de ce dernier.
On est alors surpris, voire frustré, en constatant la place considérable que les ouvrages spécialisés consacrent à l'analyse (lexicale, syntaxique, sémantique, etc.). C'est que(62) :
La bonne manière d'écrire un compilateur du langage L pour la machine M consiste à écrire un analyseur du langage L auquel, dans un deuxième temps, on ajoute - sans rien lui enlever - les opérations qui produisent du code pour la machine M.
Dans cette section nous expliquons, à travers des exemples, comment ajouter à notre analyseur les opérations de génération de code qui en font un compilateur. Il faudra se souvenir de ceci : quand on réfléchit à la génération de code on est concerné par deux exécutions différentes : d'une part l'exécution du compilateur que nous réalisons, qui produit comme résultat un programme P en langage machine, d'autre part l'exécution du programme P ; a priori cette exécution a lieu ultérieurement, mais nous devons l'imaginer en même temps que nous écrivons le compilateur, pour comprendre pourquoi nous faisons que ce dernier produise ce qu'il produit.
V-C-1. Expressions arithmétiques▲
Puisque la machine Mach 1 est une machine à pile, la traduction des expressions arithmétiques, aussi complexes soient-elles, est extrêmement simple et élégante. À titre d'exemple, imaginons que notre langage source est une sorte de « C francisé », et considérons la situation suivante (on suppose qu'il n'y a pas d'autres déclarations de variables que celles qu'on voit ici) :
entier x, y, z;
...
entier uneFonction() {
entier a, b, c;
...
y = 123 * x + c;
}Pour commencer, intéressons-nous à l'expression 123 * x + c. Son analyse syntaxique aura été faite par des fonctions expArith (expression arithmétique) et finExpArith ressemblant à ceci :
void expArith(void) {
terme();
finExpArith();
}
void finExpArith(void) {
if (uniteCourante == '+' || uniteCourante == '-') {
uniteCourante = uniteSuivante();
terme();
finExpArith();
}
}(les fonctions terme et finTerme sont analogues aux deux précédentes, avec '*' et '=' dans les rôles de '+' et '-', et facteur dans le rôle de terme). Enfin, une version simplifiée(63) de la fonction facteur pourrait commencer comme ceci :
void facteur(void) {
if (uniteCourante == NOMBRE)
uniteCourante = uniteSuivante();
else
if (uniteCourante == IDENTIFICATEUR)
uniteCourante = uniteSuivante();
else
...
}Le principe de fonctionnement d'une machine à pile, expliqué à la section 5.2.1Machines à registres et machines à pile, a la conséquence fondamentale suivante :
- la compilation d'une expression produit une suite d'instructions du langage machine (plus ou moins longue, selon la complexité de l'expression) dont l'exécution a pour effet global d'ajouter une valeur au sommet de la pile, à savoir le résultat de l'évaluation de l'expression ;
- la compilation d'une instruction du langage source produit une suite d'instructions du langage machine (plus ou moins longue, selon la complexité de l'expression) dont l'exécution laisse la pile dans l'état où elle se trouvait avant de commencer l'instruction en question.
Une manière de retrouver quel doit être le code produit pour la compilation de l'expression 123 * x + c consiste à se dire que 123 est déjà une expression correcte ; l'effet d'une telle expression doit être de mettre au sommet de la pile la valeur 123. Par conséquent, la compilation de l'expression 123 doit donner le code
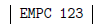
De même, la compilation de l'expression x doit donner
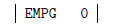
(car x est, dans notre exemple, la première variable globale) et celle de l'expression c doit donner

(car c est la troisième variable locale). Pour obtenir ces codes il suffit de transformer la fonction facteur comme ceci :
void facteur(void) {
if (uniteCourante == NOMBRE) {
genCode(EMPC);
genCode(atoi(lexeme));
uniteCourante = uniteSuivante();
}
else
if (uniteCourante == IDENTIFICATEUR) {
ENTREE_DICO *pDesc = rechercher(lexeme);
genCode(pDesc->classe == VARIABLE_GLOBALE ? EMPG : EMPL);
genCode(pDesc->adresse);
uniteCourante = uniteSuivante();
}
else
...
}La fonction genCode se charge de placer un élément (un opcode ou un opérande) dans le code. Si nous supposons que ce dernier est rangé dans la mémoire, ce pourrait être tout simplement :
void genCode(int element) {
mem[TC++] = element;
}Pour la production de code, les fonctions expArith et terme n'ont pas besoin d'être modifiées. Seules les fonctions dans lesquelles des opérateurs apparaissent explicitement doivent l'être :
void finExpArith(void) {
int uc = uniteCourante;
if (uniteCourante == '+' || uniteCourante == '-') {
uniteCourante = uniteSuivante();
terme();
genCode(uc == '+' ? ADD : SOUS);
finExpArith();
}
}
void finterme(void) {
int uc = uniteCourante;
if (uniteCourante == '*' || uniteCourante == '/') {
uniteCourante = uniteSuivante();
facteur();
genCode(uc == '*' ? MUL : DIV);
finTerme();
}
}Finalement, le code produit à l'occasion de la compilation de l'expression 123 * x + c sera donc :
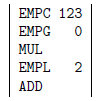
et, en imaginant l'exécution de la séquence ci-dessus, on constate que son effet global aura bien été d'ajouter une valeur au sommet de la pile.
Considérons maintenant l'instruction complète y = 123 * x + c. Dans un compilateur ultrasimplifié qui ignorerait les appels de fonction et les tableaux, on peut imaginer qu'elle aura été analysée par une fonction instruction commençant comme ceci :
void instruction(void) {
if (uniteCourante == IDENTIFICATEUR) { /* instruction d'affectation */
uniteCourante = uniteSuivante();
terminal('=');
expArith();
terminal(';');
}
else
...
}pour qu'il produise du code il faut transformer cet analyseur comme ceci :
void instruction(void) {
if (uniteCourante == IDENTIFICATEUR) { /* instruction d'affectation */
ENTREE_DICO *pDesc = rechercher(lexeme);
uniteCourante = uniteSuivante();
terminal('=');
expArith();
genCode(pDesc->classe == VARIABLE_GLOBALE ? DEPG : DEPL);
genCode(pDesc->adresse);
terminal(';');
}
else
...
}on voit alors que le code finalement produit par la compilation de y = 123 * x + c aura été :
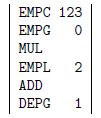
(y est la deuxième variable globale). Comme prévu, l'exécution du code précédent laisse la pile comme elle était en commençant.
V-C-2. Instruction conditionnelle et boucles▲
La plupart des langages modernes possèdent des instructions conditionnelles et des « boucles tant que » définies par des productions analogues à la suivante :
instruction → ... |
tantque expression faire instruction |
si expression alors instruction |
si expression alors instruction sinon instruction |
...La partie de l'analyseur syntaxique correspondant à la règle précédente ressemblerait à ceci(64) :
void instruction(void) {
...
else if (uniteCourante == TANTQUE) { /* boucle "tant que" */
uniteCourante = uniteSuivante();
expression();
terminal(FAIRE);
instruction();
}
else if (uniteCourante == SI) { /* instruction conditionnelle */
uniteCourante = uniteSuivante();
expression();
terminal(ALORS);
instruction();
if (uniteCourante == SINON) {
uniteCourante = uniteSuivante();
instruction();
}
}
else
...
}Commençons par le code à générer à l'occasion d'une boucle « tant que ». Dans ce code on trouvera les suites d'instructions générées pour l'expression et pour l'instruction que la syntaxe prévoit (ces deux suites peuvent être très longues, cela dépend de la complexité de l'expression et de l'instruction en question).
L'effet de cette instruction est connu : l'expression est évaluée ; si elle est fausse (C'est-à-dire nulle) l'exécution continue après le corps de la boucle ; si l'expression est vraie (c'est-à-dire non nulle) le corps de la boucle est exécuté, puis on revient à l'évaluation de l'expression et on recommence tout.
Notons expr1, expr2… exprn les codes-machine produits par la compilation de l'expression et instr1, instr2… instrk ceux produits par la compilation de l'instruction. Pour l'instruction « tant que » toute entière on aura donc un code comme ceci (les repères dans la colonne de gauche, comme αet β, représentent les adresses des instructions) :

Le point le plus difficile, ici, est de réaliser qu'au moment où le compilateur doit produire l'instruction SIFAUX β, l'adresse β n'est pas connue. Il faut donc produire quelque chose comme SIFAUX 0 et noter que la case dans laquelle est inscrit le 0 est à corriger ultérieurement (quand la valeur de β sera connue). Ce qui donne le programme :
void instruction(void) {
int alpha, aCompleter;
...
else if (uniteCourante == TANTQUE) { /* boucle "tant que" */
uniteCourante = uniteSuivante();
alpha = TC;
expression();
genCode(SIFAUX);
aCompleter = TC;
genCode(0);
terminal(FAIRE);
instruction();
genCode(SAUT);
genCode(alpha);
repCode(aCompleter, TC); /* ici, beta = TC */
}
else
...
}où repCode (pour « réparer le code ») est une fonction aussi simple que genCode (cette fonction est très simple parce que nous supposons que notre compilateur produit du code dans la mémoire ; elle serait considérablement plus complexe si le code était produit dans un fichier) :
void repCode(int place, int valeur) {
mem[place] = valeur;
}INSTRUCTION CONDITIONNELLE. Dans le même ordre d'idées, voici le code à produire dans le cas de l'instruction conditionnelle à une branche ; il n'est pas difficile d'imaginer ce qu'il faut ajouter, et où, dans l'analyseur montré plus haut pour lui faire produire le code suivant :

Et voici le code à produire pour l'instruction conditionnelle à deux branches. On note alors1, alors2… alorsk les codes-machine produits par la compilation de la première branche et sinon1, sinon2… sinonm ceux produits par la compilation de la deuxième branche :

V-C-3. Appel de fonction▲
Pour finir cette galerie d'exemples, examinons quel doit être le code produit à l'occasion de l'appel d'une fonction, aussi bien du côté de la fonction appelante que de celui de la fonction appelée.
Supposons que l'on a d'une part compilé la fonction suivante :
entier distance(entier a, entier b) {
entier x;
x = a - b;
si x < 0 alors
x = - x;
retour x;
}et supposons que l'on a d'autre part le code (u, v, w sont les seules variables globales de ce programme) :
entier u, v, w;
...
entier principale() {
...
u := 200 - distance(v, w / 25 - 100) * 2;
...
}Voici le segment du code de la fonction principale qui est la traduction de l'affectation précédente :

et voici le code de la fonction distance (voyez la section 5.2.4Compléments sur l'appel des fonctions) :
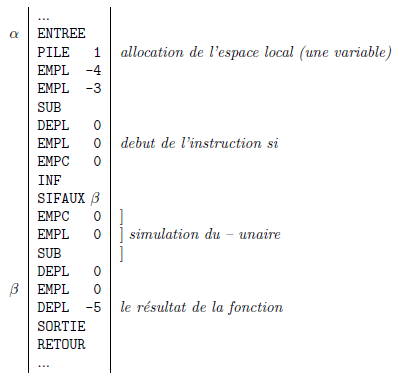
Références▲
[1] Alfred Aho, Ravi Sethi, and Jeffrey Ullman. Compilateurs. Principes, techniques et outils. Dunod, Paris, 1991.
[2] Alfred Aho and Jeffrey Ullman. The Theory of Parsing, Translating and Compiling. Prentice Hall Inc, 1972.
[3] Andrew Appel. Modern Compiler Implementation in C. Cambridge University Press, 1998.
[4] John Levine, Tony Mason, and Doug Brown. Lex & yacc. O'Reilly & Associates, Inc., 1990.
| opcode | opérande | explication |
| EMPC | valeur | EMPiler Constante. Empile la valeur indiquée. |
| EMPL | adresse | EMPiler la valeur d'une variable Locale. Empile la valeur de la variable déterminée par le déplacement relatif à BEL donné par adresse (entier relatif). |
| DEPL | adresse | DEPiler dans une variable Locale. Dépile la valeur qui est au sommet et la range dans la variable déterminée par le déplacement relatif à BEL donné par adresse (entier relatif). |
| EMPG | adresse | EMPiler la valeur d'une variable Globale. Empile la valeur de la variable déterminée par le déplacement (relatif à BEG) donné par adresse. |
| DEPG | adresse | DEPiler dans une variable Globale. Dépile la valeur qui est au sommet et la range dans la variable déterminée par le déplacement (relatif à BEG) donné par adresse. |
| EMPT | adresse | EMPiler la valeur d'un élément de Tableau. Empile la valeur qui est au sommet de la pile, soit i cette valeur. Empile la valeur de la cellule qui se trouve i cases au-delà de la variable déterminée par le déplacement (relatif à BEG) indiqué par adresse. |
| DEPT | adresse | DEPiler dans un élément de Tableau. Dépile une valeur v, puis une valeur i. Ensuite range v dans la cellule qui se trouve i cases au-delà de la variable déterminée par le déplacement (relatif à BEG) indiqué par adresse. |
| ADD | ADDition. Dépile deux valeurs et empile le résultat de leur addition. | |
| SOUS | SOUStraction. Dépile deux valeurs et empile le résultat de leur soustraction. | |
| MUL | MULtiplication. Dépile deux valeurs et empile le résultat de leur multiplication. | |
| DIV | DIVision. Dépile deux valeurs et empile le quotient de leur division euclidienne. | |
| MOD | MODulo. Dépile deux valeurs et empile le reste de leur division euclidienne. | |
| EGAL | Dépile deux valeurs et empile 1 si elles sont égales, 0 sinon. | |
| INF | INFerieur. Dépile deux valeurs et empile 1 si la première est inférieure à la seconde, 0 sinon. | |
| INFEG | INFerieur ou EGal. Dépile deux valeurs et empile 1 si la première est inférieure ou égale à la seconde, 0 sinon. | |
| NON | Dépile une valeur et empile 1 si elle est nulle, 0 sinon. | |
| LIRE | Obtient de l'utilisateur un nombre et l'empile. | |
| ECRIV | ECRIre Valeur. Extrait la valeur qui est au sommet de la pile et l'affiche. | |
| SAUT | adresse | Saut inconditionnel. L'exécution continue par l'instruction ayant l'adresse indiquée. |
| SIVRAI | adresse | Saut conditionnel. Dépile une valeur et si elle est non nulle, l'exécution continue par l'instruction ayant l'adresse indiquée. Si la valeur dépilée est nulle, l'exécution continue normalement. |
| SIFAUX | adresse | Comme ci-dessus, en permutant nul et non nul. |
| APPEL | adresse | Appel de sous-programme. Empile l'adresse de l'instruction suivante, puis fait la même chose que SAUT. |
| RETOUR | Retour de sous-programme. Dépile une valeur et continue l'exécution par l'instruction dont c'est l'adresse. | |
| ENTREE | Entrée dans un sous-programme. Empile la valeur courante de BEL, puis copie la valeur de SP dans BEL. | |
| SORTIE | Sortie d'un sous-programme. Copie la valeur de BEL dans SP, puis dépile une valeur et la range dans BEL. | |
| PILE | nbreMots Allocation et restitution d'espace dans la pile. Ajoute nbreMots, qui est un entier positif ou négatif, à SP | |
| STOP | La machine s'arrête. |